|
I obtained my M.S. degree in Software Engineering from Institute of Software, Chinese Academy of Sciences in 2026. I received my B.S. in Computer Science from University of Science and Technology, Beijing in 2023 and obtained Beijing Distinguished Graduate Award and Beijing Outstanding Graduation Thesis. I serve as a reviewer for international conferences including ICLR, CVPR, AAAI, ICME and ISMAR. My research focuses on the following areas:
I am currently a researcher at Meituan LongCat team(北斗计划), focusing on multimodal LLM and GUI agent. Email / WeChat / Github / Google Scholar |
|
|
|
- [2026-06] One paper accepted to ECCV 2026.
- [2026-05] One paper accepted to ICML 2026.
- [2026-04] One paper accepted to ICMR 2026.
- [2026-04] One paper accepted to ACL 2026.
- [2026-01] One paper accepted to TVCG 2026.
- [2025-07] One paper accepted to ACM MM 2025.
- [2025-06] Two papers accepted to ICCV 2025, including one Highlight.
- [2025-06] One paper accepted to ICME 2025.
- [2024-12] One paper accepted to AAAI 2025.
- [2024-12] One paper accepted to NeurIPS Workshop 2024.
- [2024-02] One paper accepted to IEEE VR 2024.
- [2023-06] Beijing Outstanding Graduation Design (Thesis), 2023.
- [2023-06] Beijing Distinguished Graduate Award, 2023.
|
|
|
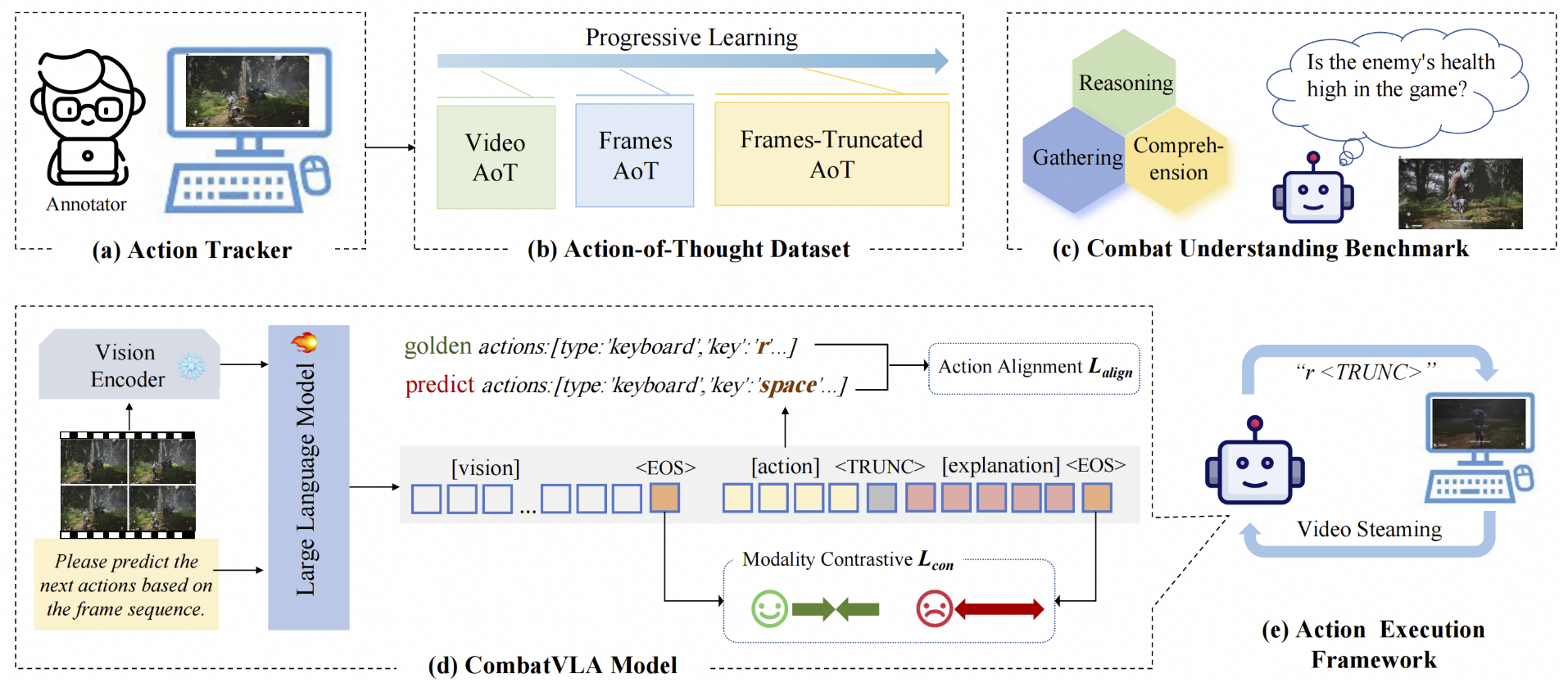
Peng Chen, Pi Bu, Yingyao Wang, Xinyi Wang, Ziming Wang, Jie Guo, Yingxiu Zhao, Qi Zhu, Jun Song, Siran Yang, Jiamang Wang, Bo Zheng Paper / Project / Code We propose CombatVLA, the first efficient visual-language action model designed for combat tasks in 3D action role-playing games. For efficient decision making, our CombatVLA is a 3B model that processes visual inputs and outputs a sequence of actions to control the game (including keyboard and mouse operations). |
|
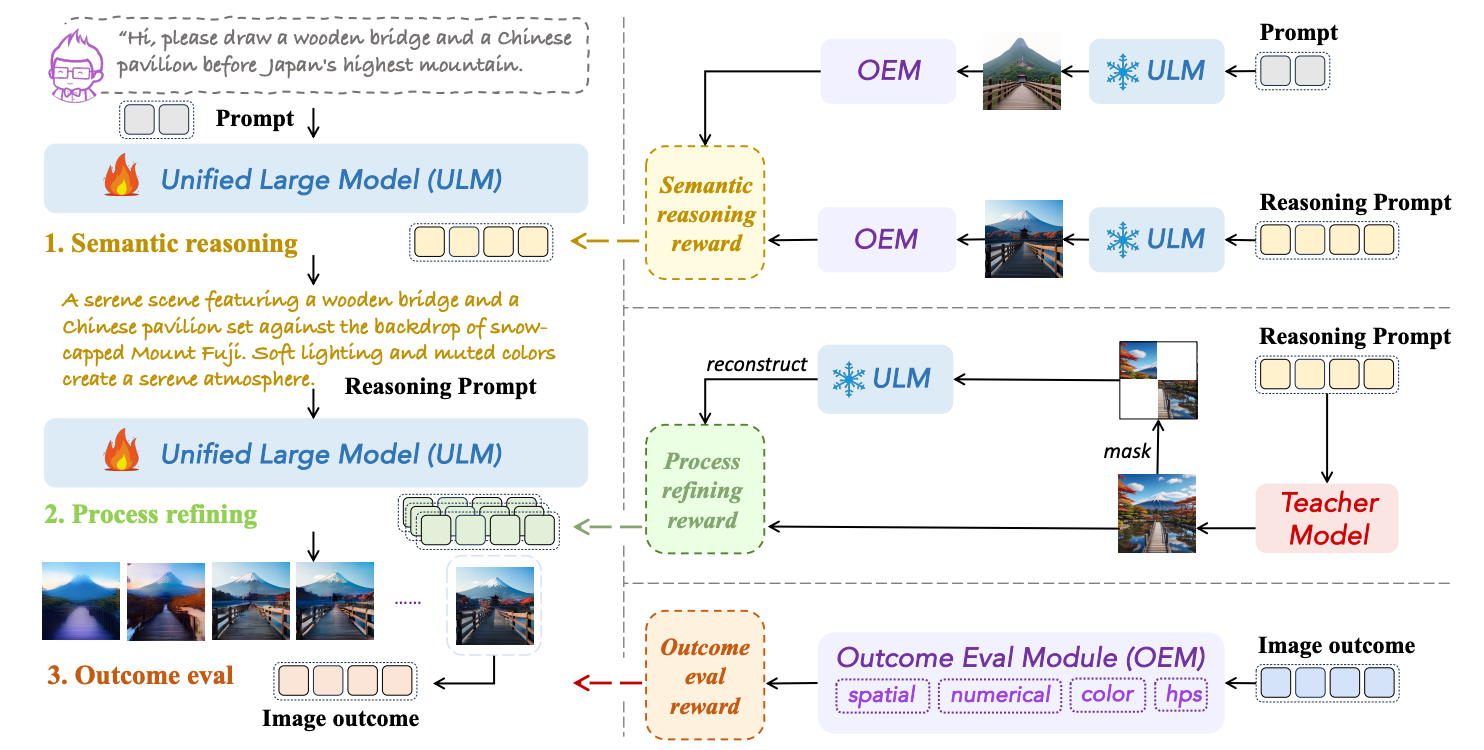
Yaqi Li*, Peng Chen*, Mingyang Han*, Pi Bu*, Haoxiang Shi, Runzhou Zhao, Yang Yao, Xuan Zhang, Jun Song Paper / Project / Code We propose a unified VLM named Visual-CoG, which leverages reinforcement learning (RL) with stage-aware rewards to provide immediate guidance throughout the image generation process, significantly improving performance on complex text-to-image tasks. |
|
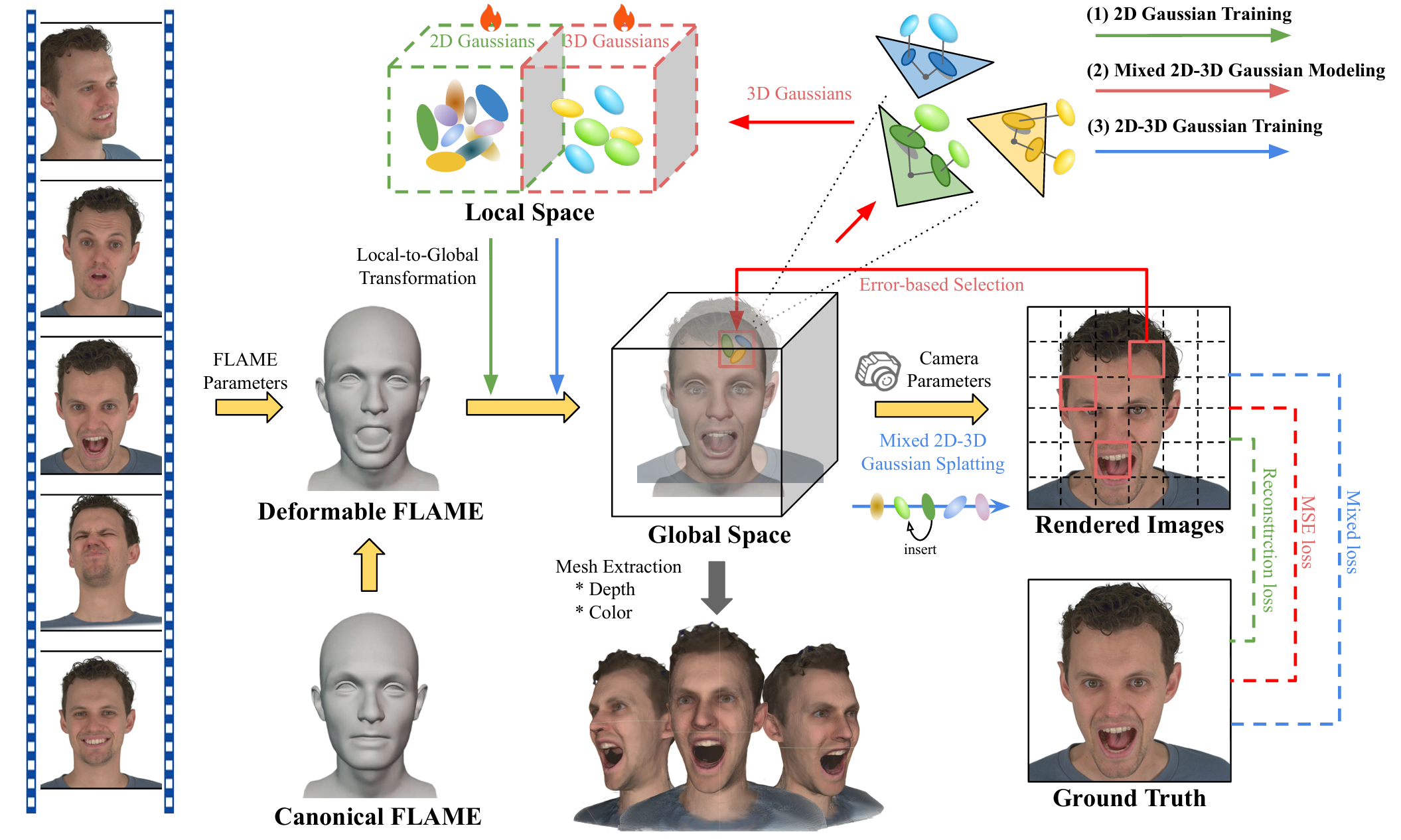
Peng Chen, Xiaobao Wei, Qingpo Wuwu, Xinyi Wang, Xingyu Xiao, Ming Lu Paper / Project / Code We use 2DGS to maintain the surface geometry and employ 3DGS for color correction in areas where the rendering quality of 2DGS is insufficient, reconstructing a realistically and geometrically accurate 3D head avatar. |
|
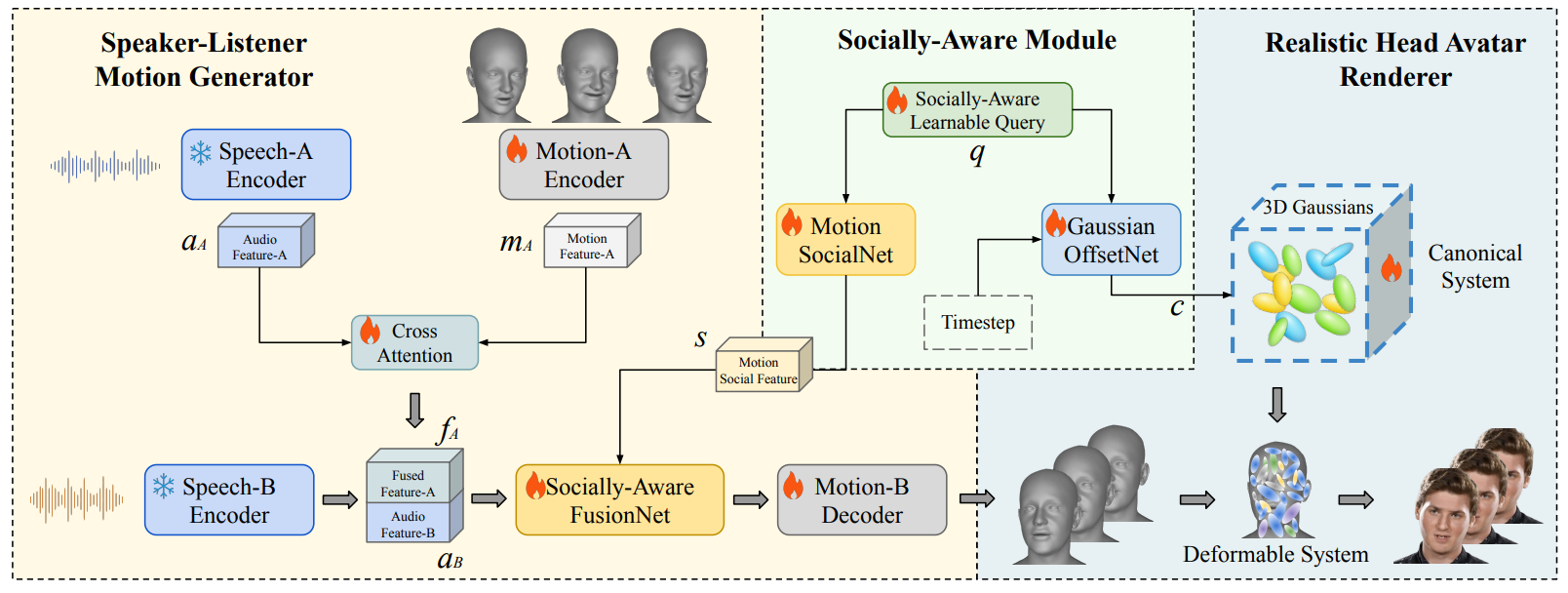
Peng Chen, Xiaobao Wei, Yi Yang, Naiming Yao, Hui Chen, Tian Feng Paper / Project / Code RSATalker achieves realistic talking head generation for multi-turn conversation. It can perceive the social relationship between the speaker and listener, thereby expressing facial movements more accurately. |
|
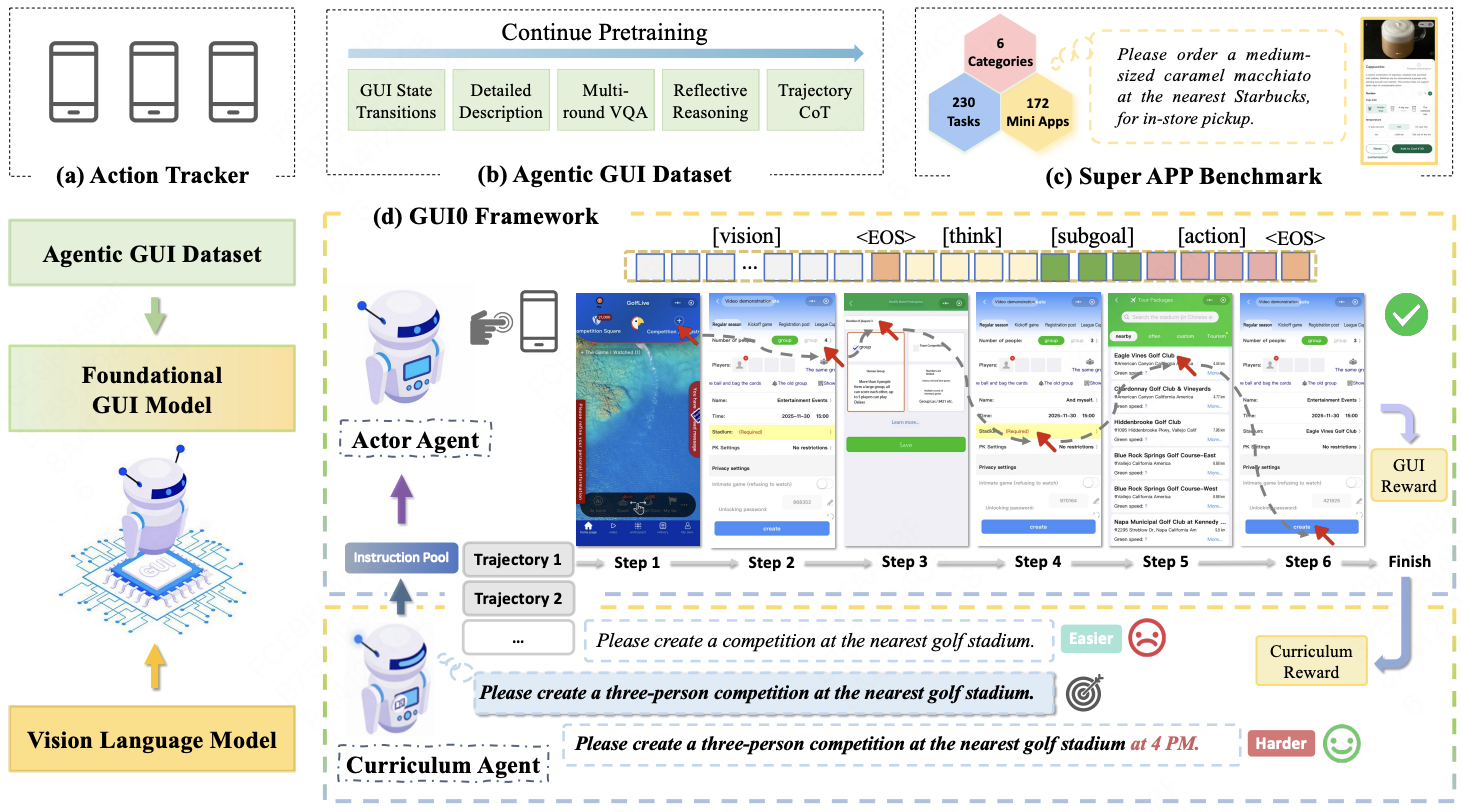
Xinyi Wang, Wei Dai, Kyle Qiao, Ke Wang, Peng Chen, Gang Cao, Kangqin, Zhongpu Wang, Xiaode Zhang, Yanming Liu, Jihao Gu, Jingtao Xu, Gong Zhi Paper / Project / Code GUI0 leverages autonomous data synthesis and dual-agent co-evolution to enable efficient automated interaction with complex, non-standard GUIs in Super App ecosystems, significantly boosting base model performance and demonstrating strong zero-shot generalization. |
|
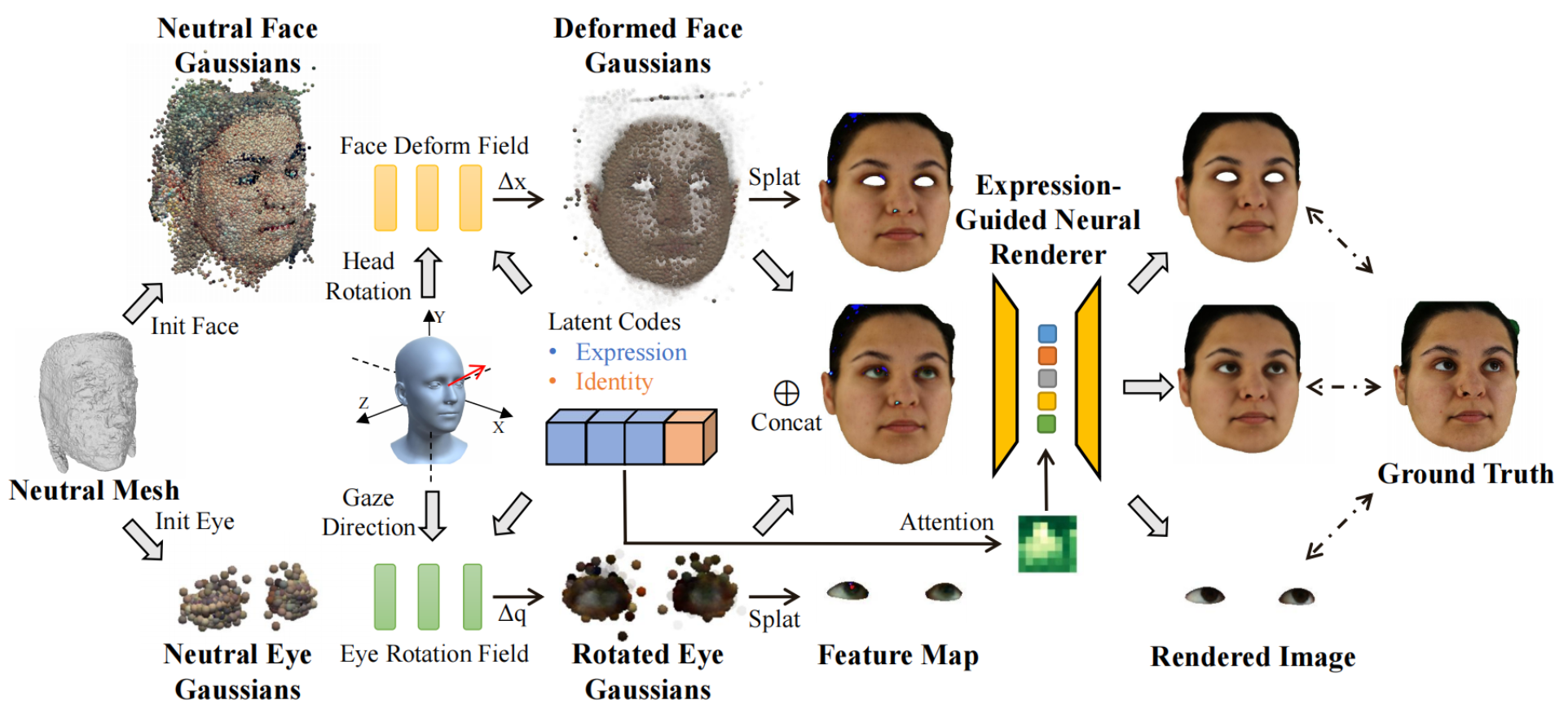
Xiaobao Wei, Peng Chen, Guangyu Li, Ming Lu, Hui Chen, Feng Tian Paper / Project / Code We propose GazeGaussian, a high-fidelity gaze redirection method that uses a two-stream 3DGS model to represent the face and eye regions separately. |
|
|
Xiaobao Wei, Peng Chen, Ming Lu, Hui Chen, Feng Tian Paper / Project / Code We propose GraphAvatar, a compact method using Graph Neural Networks (GNN) to generate 3D Gaussians for head avatar animation, offering superior rendering performance and minimal storage requirements. |
|
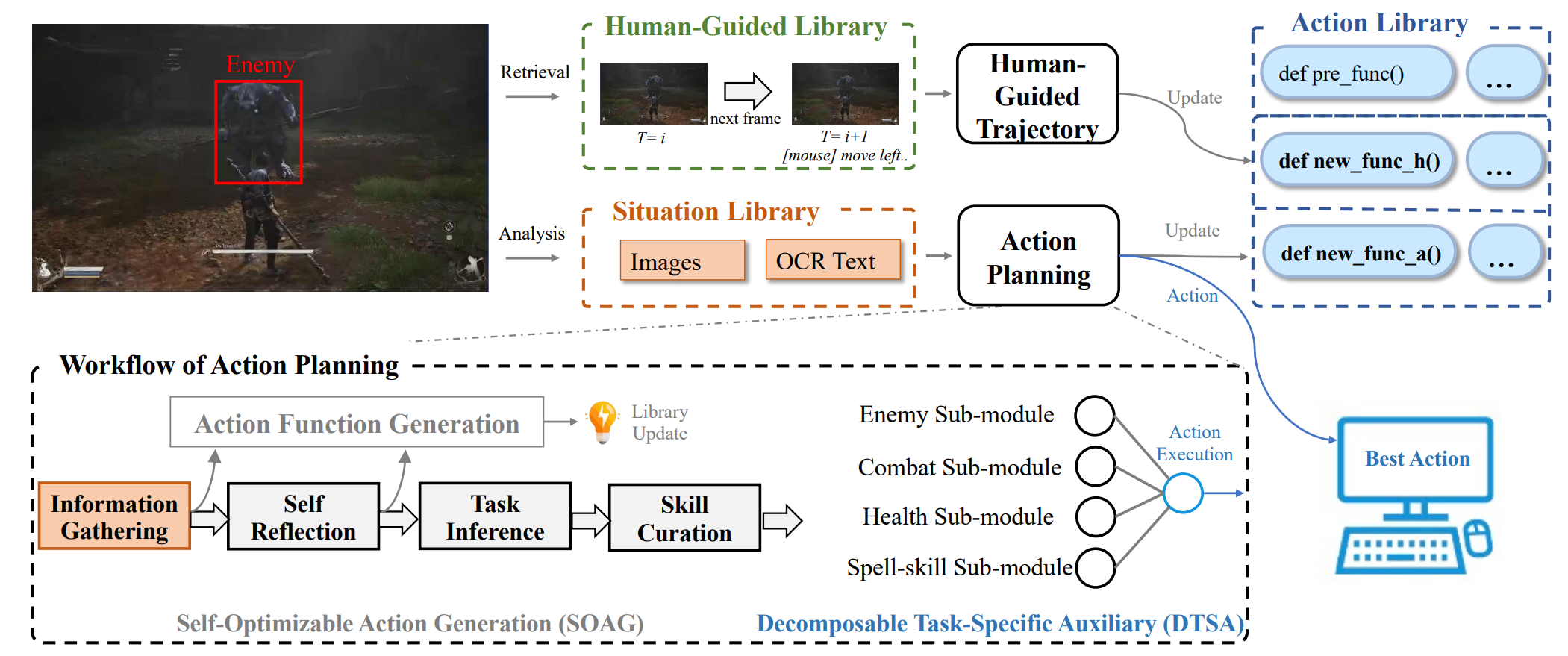
Peng Chen*, Pi Bu*, Jun Song, Yuan Gao, Bo Zheng Paper / Project We propose a novel framework named the VARP agent, which directly takes game screenshots as input and generates keyboard and mouse operations to play the ARPG. |
|
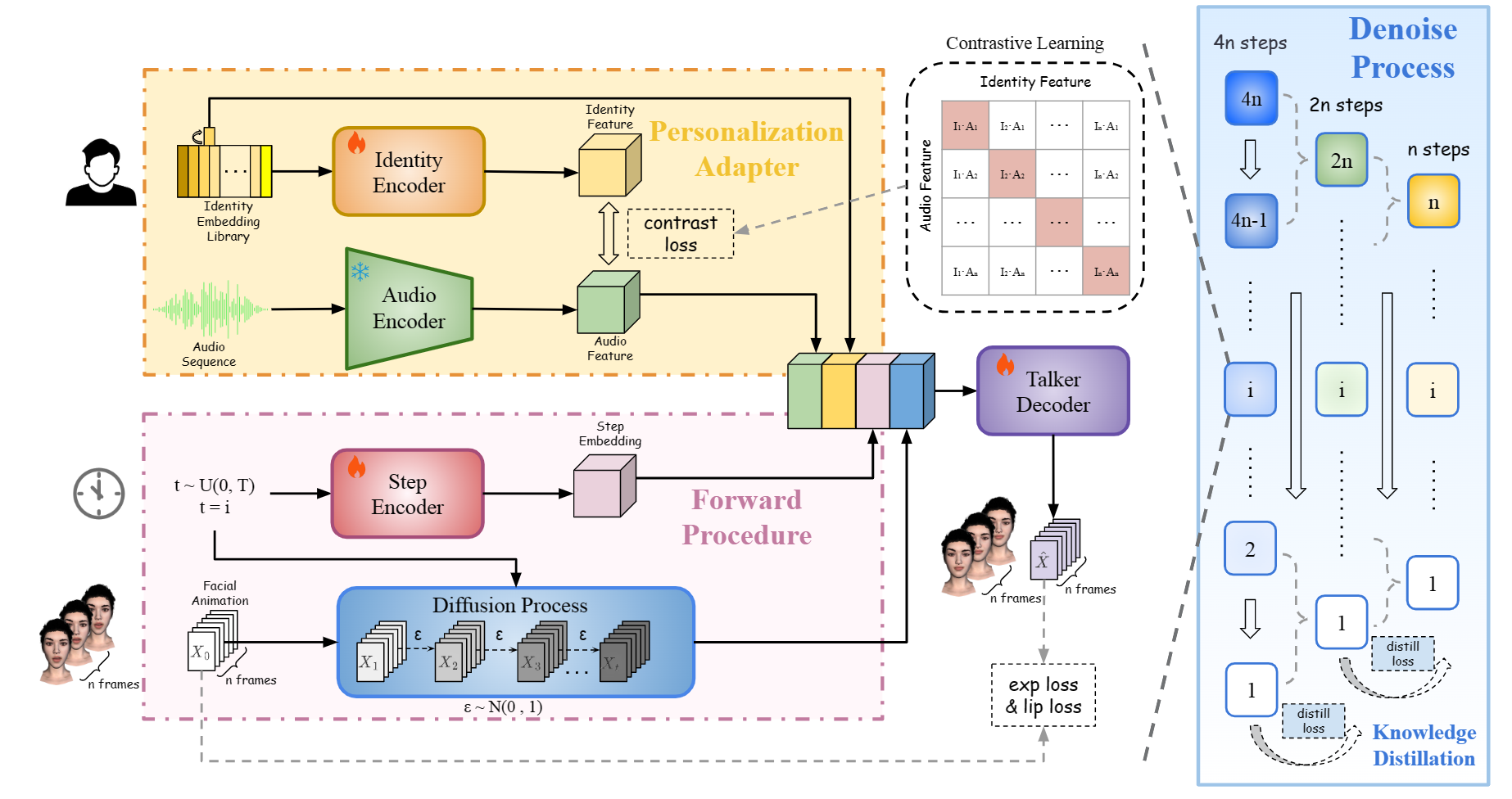
Peng Chen, Xiaobao Wei, Ming Lu, Hui Chen, Feng Tian Paper / Project / Code We propose DiffusionTalker, a diffusion-based method that utilizes contrastive personalizer to generate personalized 3D facial animation and personalizer-guided distillation for acceleration and compression. |
|
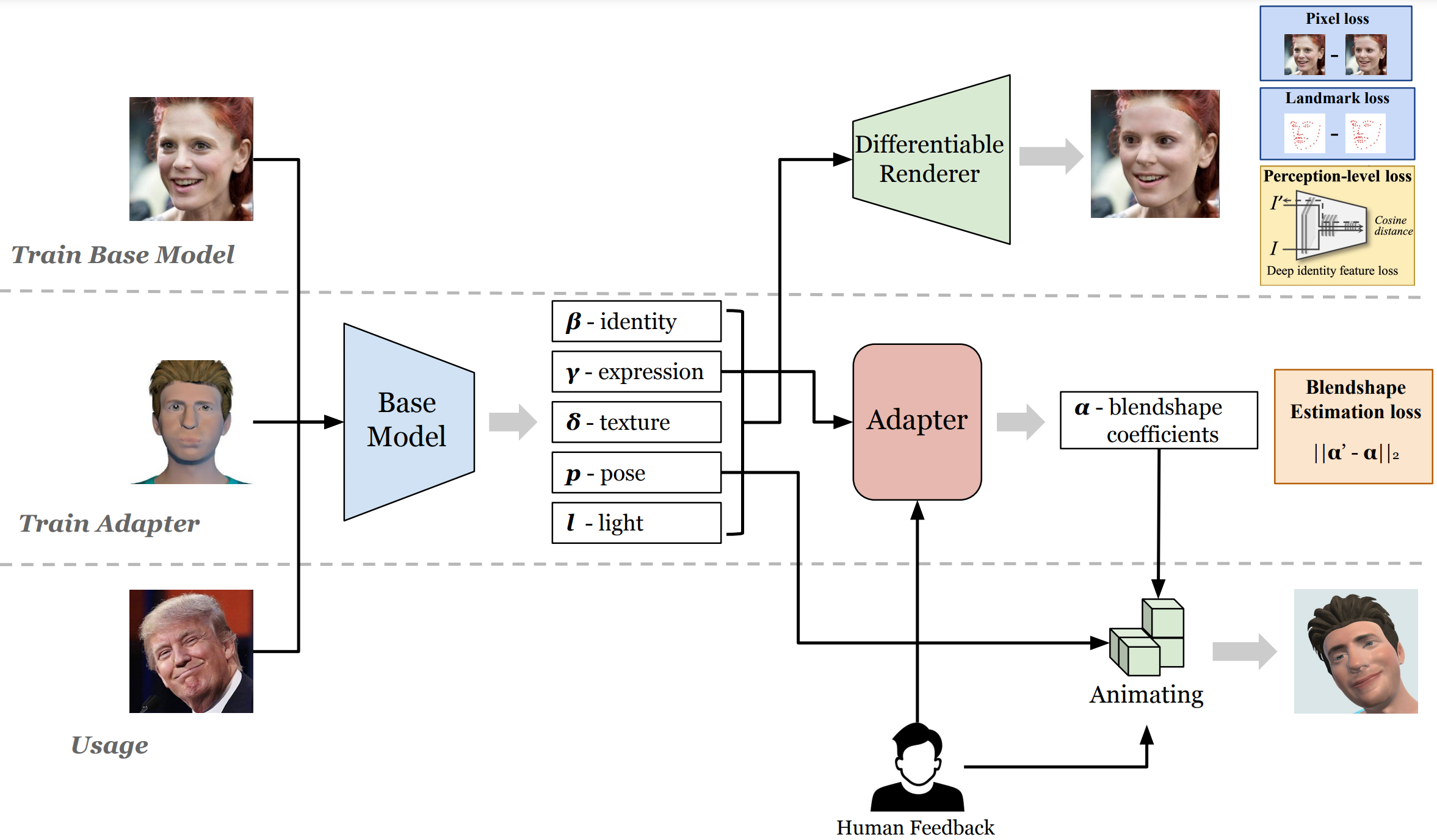
Zechen Bai*, Peng Chen*, Xiaolan Peng, Lu Liu, Naiming Yao, Hui Chen, Feng Tian Paper / Code Given a target facial video as reference, bring your own character into our solution integrated with Unity3D, it automatically generates facial animation for the virtual character. |
|
|
-
[02/2026 - 07/2026] Meituan, M17, LongCat (北斗计划)
Research intern focused on the mid-training and post-training of LongCat multimodal foundational model, with a particular emphasis on GUI-agent capabilities, especially computer-use agents.
-
[05/2025 - 12/2025] Tencent, TEG, Hunyuan (青云计划)
Research intern for RL fine-tuning of VLM foundational models and distillation acceleration of video generation models.
-
[04/2024 - 05/2025] Alibaba, Taotian, Future Living Lab
Research intern for VLM, focusing on game and GUI agent, RL-based thinking model, and unified language models.
-
[11/2023 - 04/2024] AMD, Xilinx AI
Research intern for diffusion-based AIGC, especially focused on improving ControlNet and Stable Diffusion for image generation.
-
[07/2023 - 08/2023] Baidu, ACG
Research intern for LLM evaluation, focusing on the automated evaluation of text-based question-answering tasks for the Wenxin large language model and reward model.